Regras de Negócio
1.0 Conceitos Gerais
Quando falamos de contas ou de indicadores fundamentalistas estamos falando da parte mais importante do sistema. Essas duas entidades são a matéria prima para a construção de relatórios de análises horizontais e verticais. Por tanto em volta dessas entidades existem uma série de especificações:
1.1 Demostrações Consolidadas e Individuais
A emissão de balanços de uma empresa pode ser categorizada como Individual ou Consolidada.
Balanço consolidado é o somatório, ou seja, a consolidação das demonstrações contábeis de uma ou mais empresas do mesmo grupo empresarial.
A diferença entre em balanço consolidado e individual é que no consolidado é demonstrado toda as informações da empresa junto com aquelas que ela tem participação, já no individual o balanço é apenas da própria empresa.
fonte: https://comoinvestir.thecap.com.br/balanco-consolidado
1.2 Segmentos de Atuação
Como dito anteriormente, empresas de diferentes segmentos vão ter defasagem em seus balanços patrimoniais.
Mais informações sobre segment na seção anterior
1.3 O trio Id-IsConsolidated-SegmentId
Contas e indicadores são identificados através de um id natural, se é consoliadado ou individual e por fim a qual segmento está inserido. Por exemplo:
Contas
| Id | IsConsolidated | SegmentId |
|---|---|---|
| 1.01.01 | true | 1 |
| 1.01.01 | false | 1 |
| 1.01.01 | true | 2 |
| 1.01.01 | false | 2 |
| 1.01.01 | true | 3 |
| 1.01.01 | false | 3 |
Indicadores
| Id | IsConsolidated | SegmentId |
|---|---|---|
| 1 | true | 1 |
| 2 | false | 1 |
| 3 | true | 2 |
| 4 | false | 2 |
| 5 | true | 3 |
| 6 | false | 3 |
De maneira geral, existe 6 combinações dado um Id de uma conta ou de um indicador
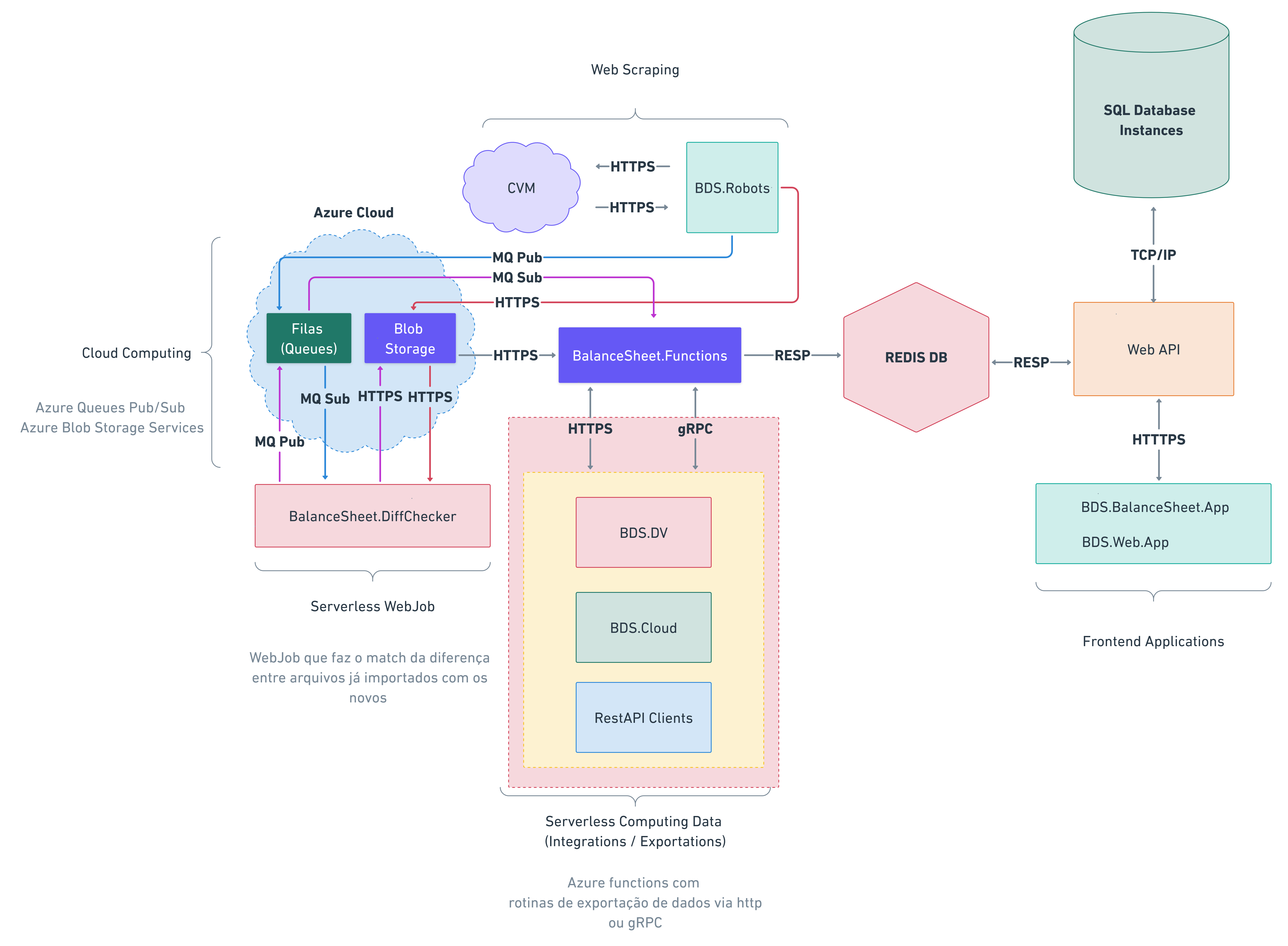
2.0 Processo de importação de dados
Os dados publicados por organizações como o CVM (Comissão de Valores Mobiliários) são capturados pelo projeto BDS.Robots e enviados para blob storages específicos na nossa Cloud Computing. Uma vez publicados nestes blob storages o BDS.Robots irá enviar mensagens nas filas para notificar os consumidores destas mesmas sobre a importação do arquivo formando assim o sistema Pub/Sub.
Os micro-serviços de importação do projeto BalanceSheet (Azure Functions em Python) são acionados através do Queue Trigger para que o processo de importação seja iniciado.
2.1 Tecnologias
2.1.1 Python
Os processos de importação são preferencialmente escritos em Python pelo fato de ser uma linguagem rápida em questões de I/O e por possuir uma biblioteca completa chamada Pandas
É definido uma estrutura de pipeline no código fonte, onde cada estágio equivale a um estado do processo. Em suma teremos este template de pipeline:
-
Query Stage: Estágio que fará buscas de dados necessário para o processo como um todo em API's. O resultado dessea query é inserido dentro de uma variável container ou wrapper afim de facilitar a passagem por parâmetros para os próximos estágios.
-
Read Stage: Estágio que vai ler os dados do arquivo que está importado transformando-os em dataframes para fácil manipulação
-
Format Stage: Estágio que vai formatar e validar os dados contidos do dataframe. Este estágio, como sequência, vai criar dicts (Objetos python) a partir dos dataframes gerados no estágio anterior
-
Segregate Stage: Este estágio vai segregar os objetos formatados afim de criar entidades reais do sistema.
-
Aggregate Stage: Este estágio vai pegar os dados segregados e irá juntá-los num objeto root para ser enviado ao banco de dados em cache de maneira padronizada. Esse objeto root possui um Id (UUID), Data de importação além de outros metadados variados. Vale notar que esse estágio aggrega os dados em pedaços de x em x objetos. Por exemplo pra cada 500 balanços, um objeto root.
-
Save Stage: Estágio que vai persistir no banco de dados em cache e logo após irá notificar a API para que a mesma inicie o hosted service de importação, que será responsável por persistir os dados na base relacional e em outras fontes de dados caso necessário.
2.1.1 Redis DB
O banco de dados Redis DB é uma excelente solução para CacheDB e é usado com mais frequência nos processos de importação. Já que os micro-serviços de importação sempre persistem os dados no redis db para que os dados não se percam caso a ocorra algum problema durante o processo de importação por parte da API
2.2 A Importação
2.2.1 Companies
A importação de empresas é a mais simples e mais rápida que tem. A CVM divulga em seu portal de dados (Confira Portal CVM aqui) dados cadastrais de empresas. Segue abaixo a principal fonte de cada tipo de empresa:
2.2.2 Balanços
A importação de balanços é mais complexa e mais demorada. Os arquivos de balanços patrimonias anuas e trimestrais costumam ser gigantescos. Isso mais o fato dos dados serem naturalmente desestruturados contribui para um longo processo de validação e estruturação que é feita no momento da importação pelos micro-serviços de importação (Azure Functions)